Abstract
Text-to-image diffusion models are a class of deep generative models that have demonstrated an impressive capacity for high-quality image generation. However, these models are susceptible to implicit biases that arise from web-scale text-image training pairs and may inaccurately model aspects of images we care about. This can result in suboptimal samples, model bias, and images that do not align with human ethics and preferences. In this paper, we present an effective scalable algorithm to improve diffusion models using Reinforcement Learning (RL) across a diverse set of reward functions, such as human preference, compositionality, and fairness over millions of images. We illustrate how our approach substantially outperforms existing methods for aligning diffusion models with human preferences. We further illustrate how this substantially improves pretrained Stable Diffusion (SD) models, generating samples that are preferred by humans 80.3% of the time over those from the base SD model while simultaneously improving both the composition and diversity of generated samples.
Results
Human Preferences
We fine-tune Stable Diffusion 2 with ImageReward, which was trained on human assessments of text-image pairs, to optimize for human preferences. We show the results from our fine-tuned model on real-user prompts here and provide qualitative comparison with other reward optimization methods below. By evaluating our model on both in-domain dataset DiffusionDB and out-of-domain test set PartiPrompts, we demonstrate that our trained model generates more visually appealing images compared to the base SDv2 model, and it generalizes well to unseen text prompts.
All images below are generated with the same random seeds. Our outputs are better aligned with human aesthetic preferences, favoring finer details, focused composition, vivid colors, and high contrast.





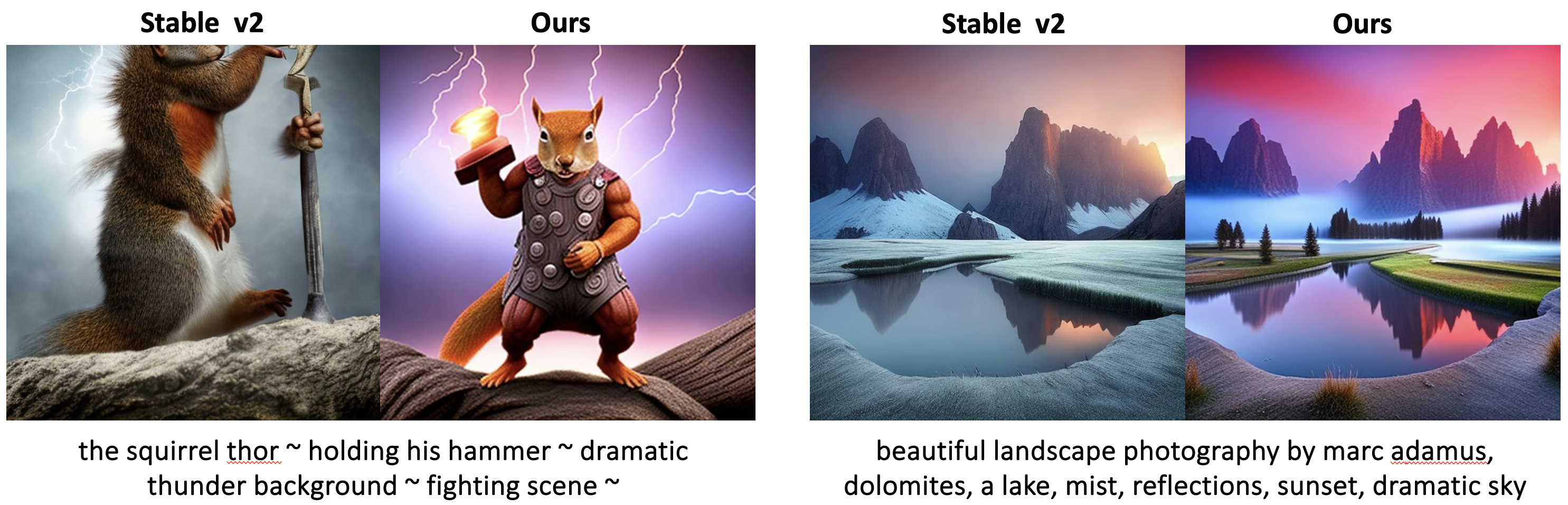



Baseline Comparison
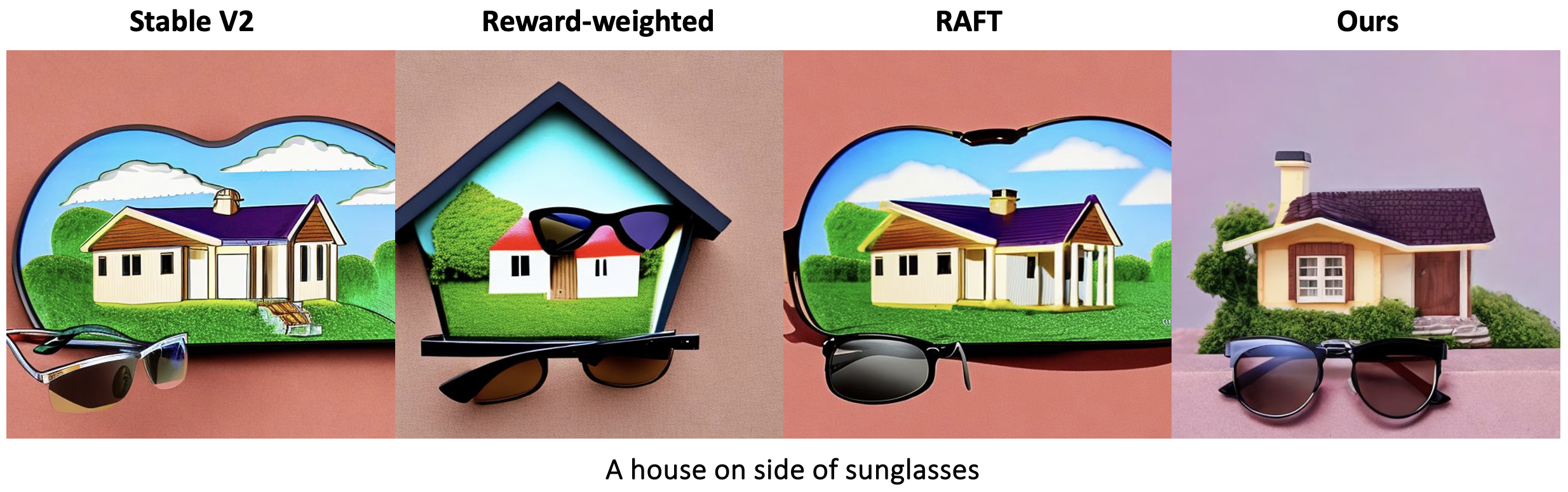
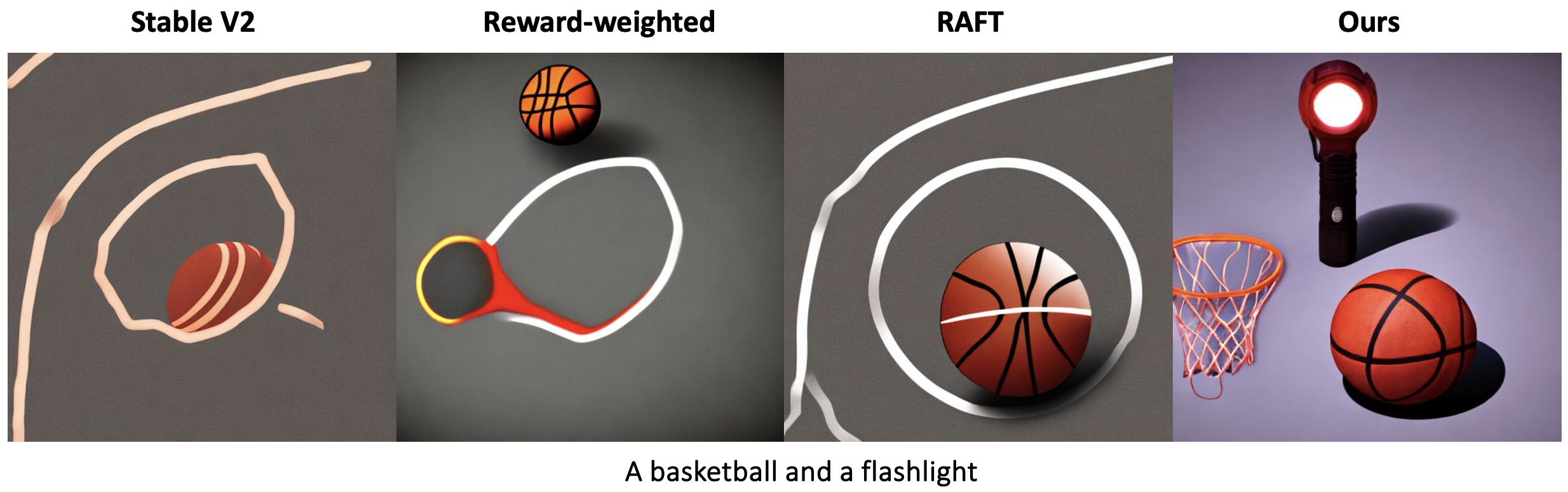
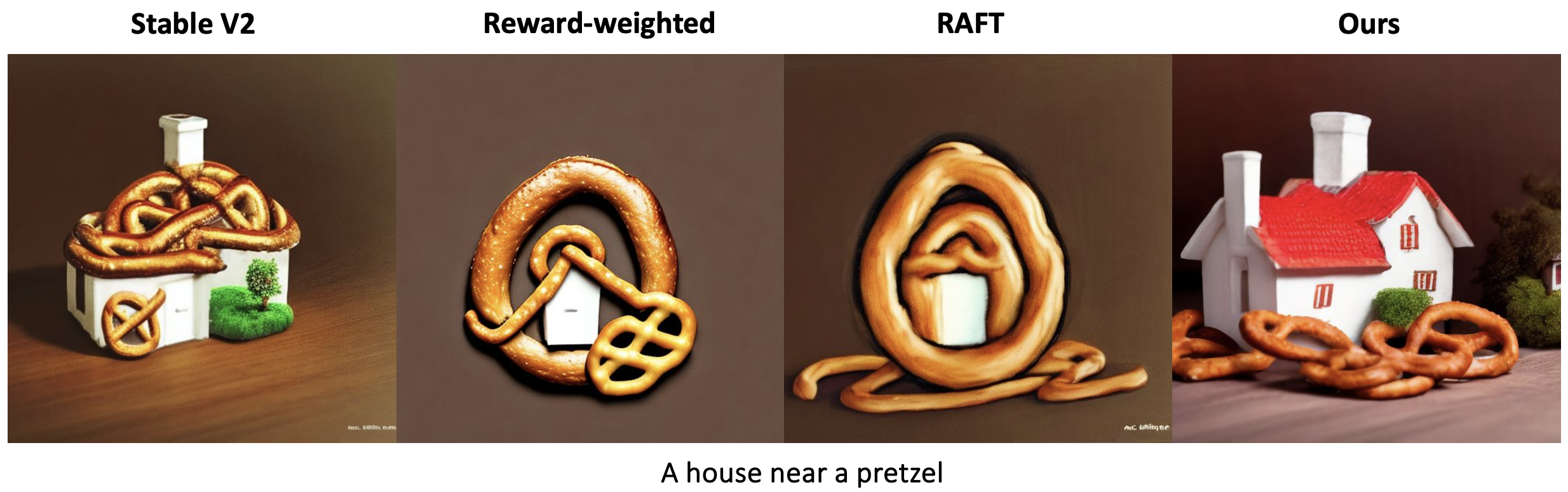
Prior reward fine-tuning methods for diffusion models mainly fall under three categories: reward-based loss reweighting, dataset augmentation, and backpropagation through the reward model. We compare against a variety of baseline methods, including ReFL, RAFT, DRaFT and Reward-weighted, covering the three different methodologies.





















Skintone Diversity
The training of diffusion models is highly data-driven, relying on billion-sized datasets that are randomly scraped from internet. As a result, the trained models may contain significant social bias and stereotypes. For example, it has been observed that text-to-image diffusion models commonly exhibit a tendency to generate humans with lighter skintones. We aim to mitigate this bias by explicitly guiding the model using a skintone diversity reward. During training, we use a reward function that encourages a uniform distribution among different skintones. We observe that our fine-tuned model greatly reduces the skintone bias embedded in the pretrained SDv2 model, especially for occupations with more social stereotypes or biases inherent in the pretraining dataset.










Object Composition
As diffusion models often fail to accurately generate different compositions of objects in a scene, we further explored using our RL framework in ensuring compositionality with diffusion models. We use relationship terms such as “and,” “next to,” “near,” “on side of” and “beside” to produce captions that designate a spatial relationship between two objects and use the generated captions for training and evaluating the compositional skill of the model.



A cake next to a desk.

Chips beside a blue jay.

An apple and a pillow.


BibTeX
@misc{zhang2024largescale,
title={Large-scale Reinforcement Learning for Diffusion Models},
author={Yinan Zhang and Eric Tzeng and Yilun Du and Dmitry Kislyuk},
year={2024},
eprint={2401.12244},
archivePrefix={arXiv},
primaryClass={cs.CV}
}